


Daytona built and ran these benchmarks. We are publishing them because we wanted to understand how our execution layer compares with infrastructure teams already operate. The workloads, commands, resource limits, and repository were held constant across all five systems, and the methodology is described below.
TL;DR
The Hidden Infrastructure Tax: Unlike toy simulators, coding-agent reinforcement learning (RL) interacts with real software environments (shells, filesystems, package managers). This introduces significant, often-overlooked latency into the training loop.
Benchmarking the Execution Layer: We measured the end-to-end latency of five infrastructure archetypes (Docker, EC2, Kubernetes, ECS/Fargate, and Daytona) across fresh episode startups and multi-step trajectories.
Compounding Costs at Scale: Minor delays in environment provisioning and per-action execution compound massively. At 10,000 trajectories, aggregate worker-hours ranged from 36 hours (Daytona) to 449 hours (ECS/Fargate).
Beyond GPU-Hours: While most RL metrics focus on model performance and GPU compute, rollout throughput is heavily bottlenecked by how quickly environments can be scheduled, acted in, and reset.
The Takeaway: Optimizing your execution substrate—whether through deep Kubernetes tuning or hosted sandbox layers—is now a critical requirement for scaling coding-agent RL.
Coding-agent RL has a hidden infrastructure tax. In our SWE-agent-style bug-fix workload, a 50-action trajectory took 12.9 seconds on Daytona, compared with 20.1 seconds on Kubernetes, 30.5 seconds on EC2, and 161.5 seconds on ECS/Fargate. At 10,000 trajectories and 50 actions each, that difference becomes 36 aggregate worker-hours on Daytona, 56 on Kubernetes, and 449 on Fargate.
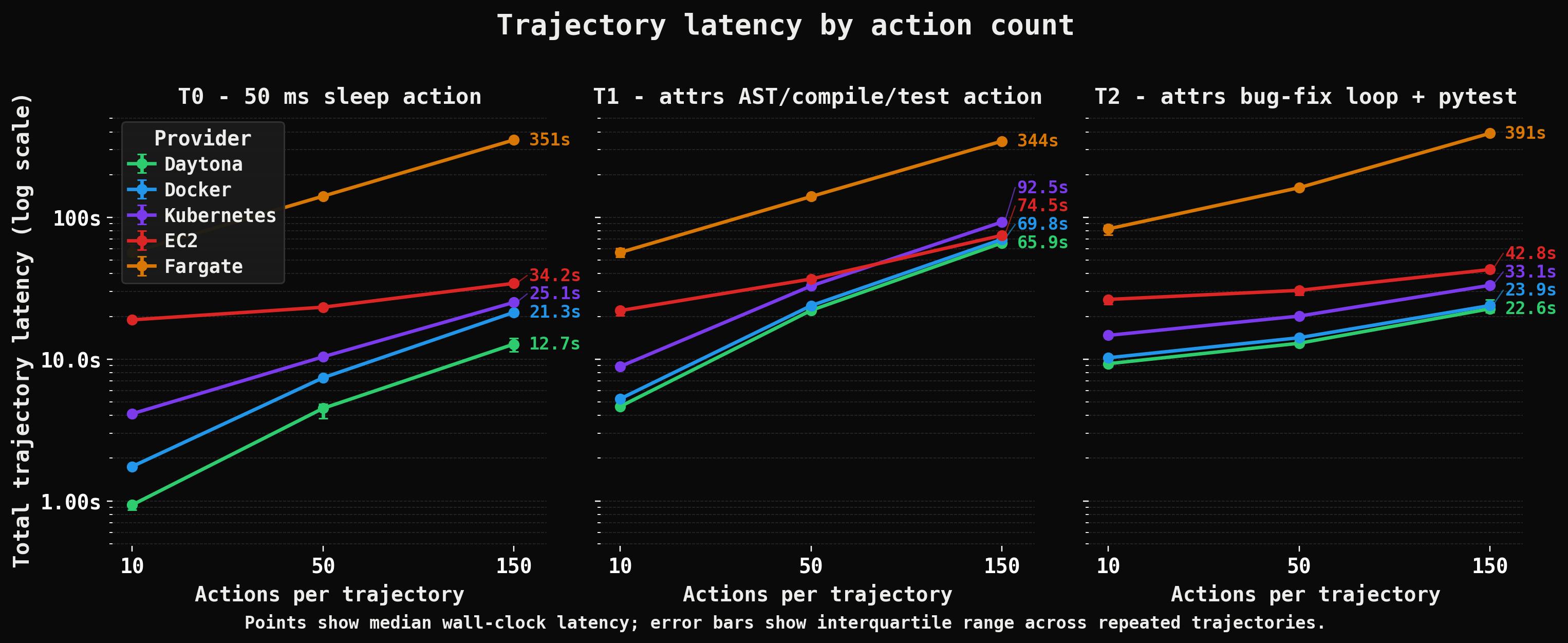
Trajectory latency at 10, 50, and 150 actions. This is the most important view for RL rollouts because it captures the cost that training systems experience: startup plus repeated command execution. Short trajectories expose cold-start and setup costs; longer trajectories show how per-action overhead compounds over time.
The reason this compounds is simple: coding-agent RL systems do not interact with a lightweight simulator. They act through shells, filesystems, repositories, package managers, and tests. Each command is an action, and the sandbox implements the environment’s step function. The environment is therefore not a negligible part of the loop. It is a distributed execution system.
Most RL reports account for model performance and GPU-hours. Far fewer break down the latency between model actions and environment feedback. Sandbox provisioning, command execution, environment reset, scheduling, and trajectory orchestration all sit in that path. This gap is especially visible in coding-agent benchmarks and training environments such as Terminal-Bench, SWE-bench, SWE-RL, and SWE-Gym, where the environment is not a toy simulator but a real software task with setup, execution, and feedback. A run with 10,000 trajectories and 50 actions per trajectory issues 500,000 commands across the rollout fleet. A 100ms per-action overhead translates into roughly 14 hours of aggregate worker-time, which is parallelism-invariant. It shows up as either added wall-clock at low parallelism, or as added compute cost from more rollout workers held longer.
We measured the execution layer directly by comparing five infrastructure archetypes RL teams commonly choose between. The goal was to isolate how each substrate affects the end-to-end latency of agent rollouts.
What We Measured
We benchmarked the execution path around coding-agent RL rollouts: creating a clean environment, running agent-issued commands, and completing multi-step trajectories. Each provider executed the same commands in the same order, with environments constrained to 1 vCPU and 1 GiB RAM. This kept the workload fixed and made the infrastructure backend the primary variable under test.
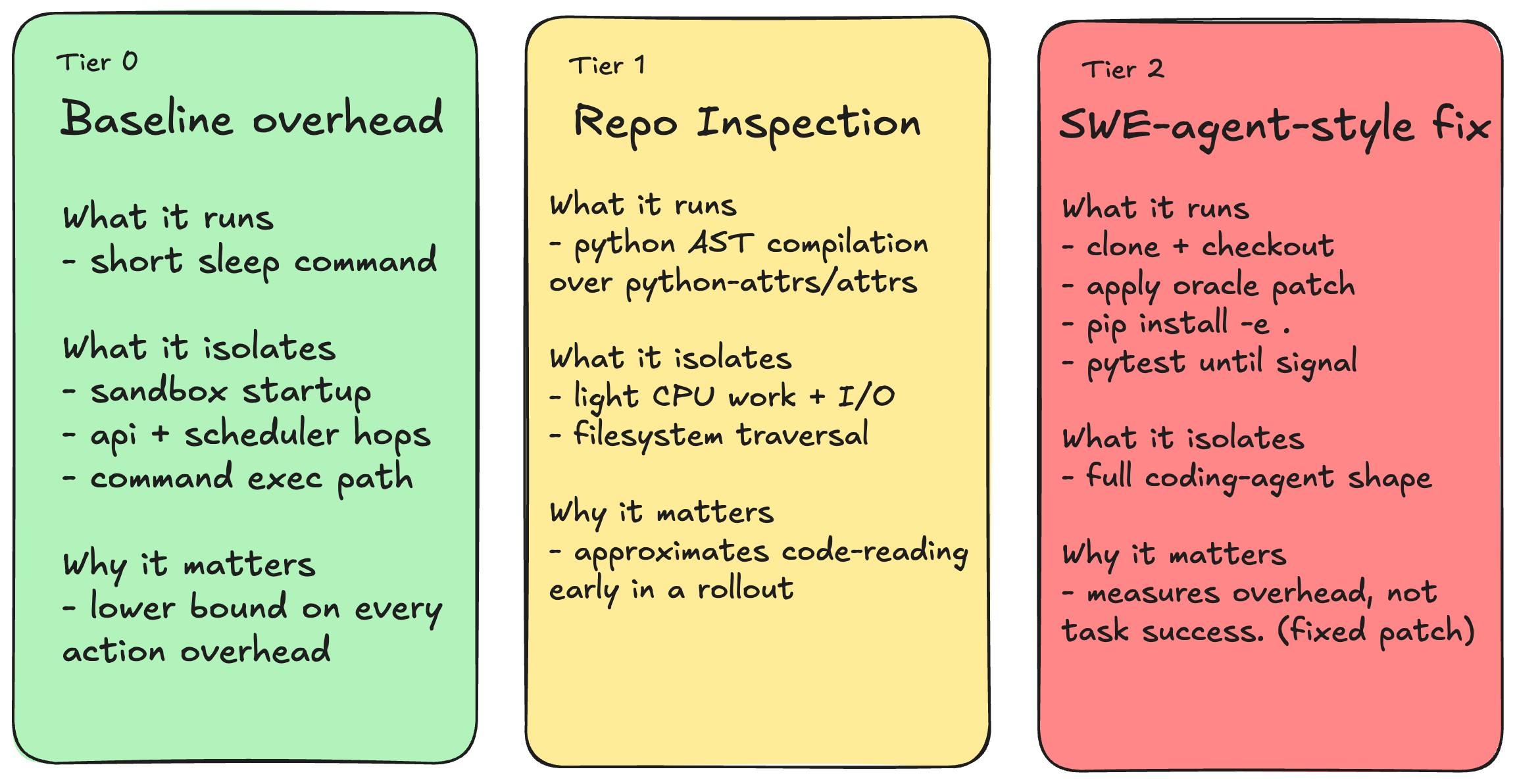
The three tiers move from synthetic infrastructure overhead to realistic coding-agent behavior. Tier 0 isolates the command-execution path itself, Tier 1 adds lightweight repository inspection, and Tier 2 adds the setup, dependency installation, patching, and test feedback loop common to SWE-agent-style tasks.
Tier 2 is meant to resemble the infrastructure shape of recent software-engineering agent training work: repository checkout, code modification, dependency setup, and test feedback.
We measured two modes. Fresh episode latency captures the time required to obtain a clean, ready-to-use environment before the first agent action. Trajectory latency captures total wall-clock time for rollouts of 10, 50, and 150 actions, including the fresh episode cost.
Where the Latency Shows Up
The latency shows up in two places: before the first action, and between every action after that.
Fresh episode latency captures the cost paid once per trajectory: creating a clean environment, scheduling it, preparing it, and making it ready for the first agent command. This cost matters most when rollouts are short, resets are frequent, or the training run launches many trajectories in parallel.

Fresh episode latency across providers and workload tiers. This view isolates the fixed cost paid before useful agent work begins: environment creation, setup, scheduling, and readiness before the first action.
The second cost is per-action overhead. Once the environment exists, the agent still needs to issue commands, wait for them to run, and receive observations back. That path is exercised every time the agent calls the shell. Even small differences at this layer compound over long trajectories and large rollout fleets.
The pattern is clearest in the Tier 2 workload, which has the same infrastructure shape as many coding-agent tasks: repository setup, code modification, dependency installation, and test feedback.
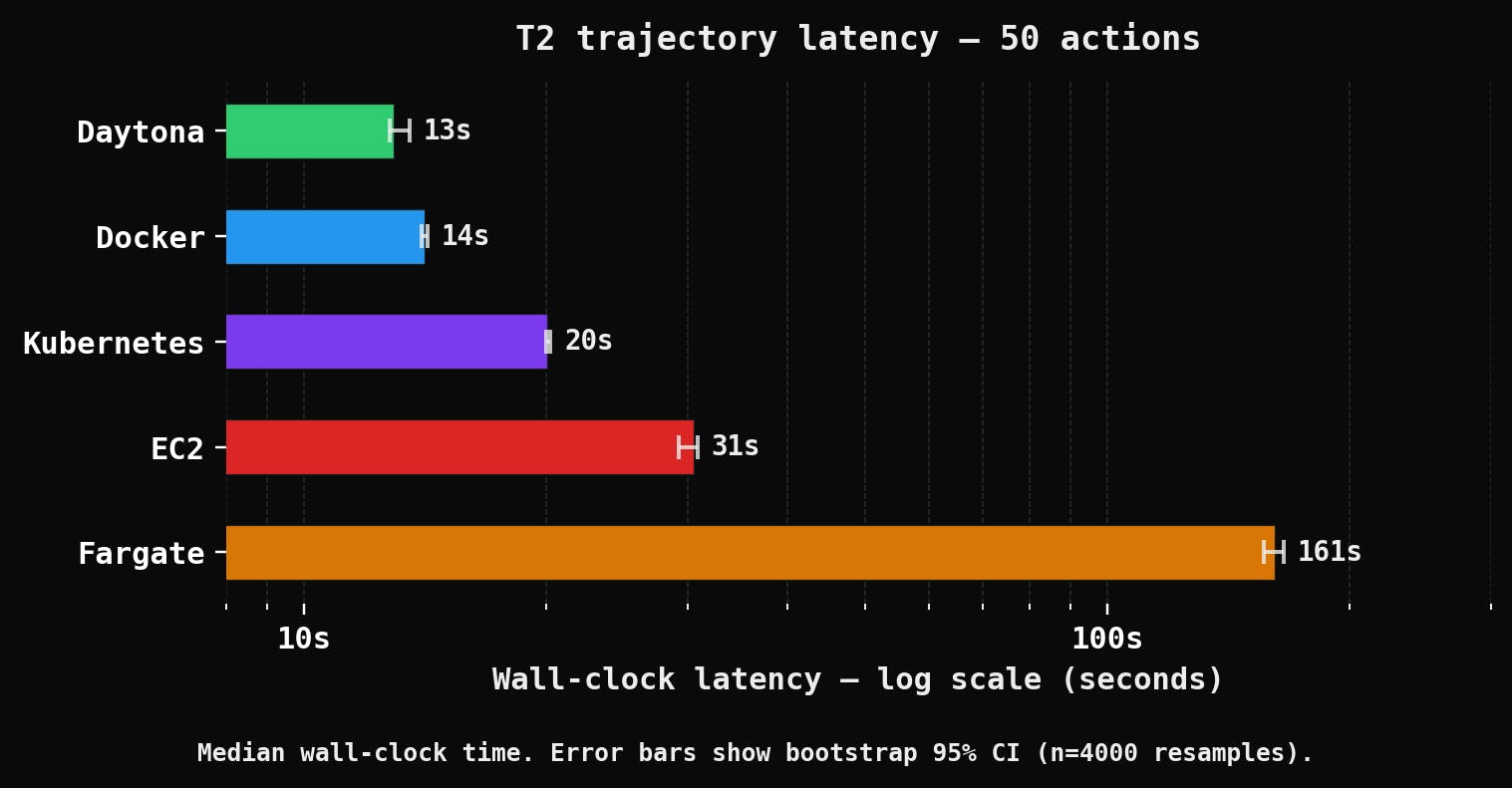
The point is not only that one system starts faster. It is that fixed startup latency and repeated command latency interact. Short trajectories expose provisioning and setup costs. Longer trajectories show how per-action overhead accumulates. In both cases, the execution substrate changes the amount of time it takes to produce rollout data.
This is why the comparison has to happen at the infrastructure level, not just at the command level. Each substrate represents a different way of creating environments, isolating execution, scheduling work, and returning observations to the agent. Docker provides a useful single-machine lower bound, but that performance does not imply scalability for distributed training. EC2, Kubernetes, and ECS/Fargate expose different tradeoffs between control, orchestration overhead, isolation, and operational complexity. Daytona is designed around agent workloads that require many short-lived, isolated, stateful environments with repeated command execution.
What This Costs at Training Scale
At small scale, rollout latency looks like seconds per trajectory. At training scale, it becomes worker-hours.
For a run with 10,000 trajectories, 50 actions per trajectory, and 500 parallel rollout workers, the Tier 2 results translate into the following aggregate cost:
| Execution Environment | Per-Trajectory Cost(s) | Wall-Clock Time per Run (hours) | Aggregate Worker-Hours | Overhead vs. K8's (worker-hours) |
|---|---|---|---|---|
| Docker | 14.1 | 0.1 | 39 | -17 |
| EC2 | 30.5 | 0.2 | 85 | +29 |
| K8's | 20.1 | 0.1 | 56 | - |
| Fargate | 161.5 | 0.9 | 449 | +393 |
| Daytona | 12.9 | 0.1 | 36 | -20 |
The important column is aggregate worker-hours. Wall-clock time changes with parallelism, but worker-hours scale with the total amount of rollout work. Faster execution substrates reduce the amount of worker time consumed to produce the same number of trajectories.
In this model, Daytona uses 36 aggregate worker-hours, compared with 80 for Kubernetes and 449 for ECS/Fargate. The difference is not just benchmark latency. It is rollout capacity that can either produce more trajectories, reduce cluster cost, or shorten the time between policy updates.
When the Rollout Tax Matters
These measurements matter most when rollout generation is dominated by many short-lived, command-driven environments. That includes training setups with large numbers of trajectories, frequent environment resets, high parallelism, or agents that emit many shell-level actions before receiving reward.
In these regimes, both fixed startup latency and per-action overhead compound. Cold starts are paid once per trajectory. Command-execution overhead is paid at every agent step.
We observed the largest effect in short and medium trajectories, where provisioning and orchestration costs represent a meaningful share of end-to-end time. As trajectories become longer, startup cost is increasingly amortized, but per-action overhead can still matter if the agent emits many commands.
These results matter less when environments are long-lived, resets are rare, training is primarily GPU-bound, or agents take only a small number of external actions. In those cases, the execution layer may not be the bottleneck yet.
Why This Layer Gets Ignored
This layer is easy to miss because most RL work is organized around the learning system: the algorithm, reward design, data, evaluation, and final model performance. GPU-hours are counted because they are expensive and visible, while the execution path between model action and environment feedback is usually treated as implementation detail.
There is also a practical reason it gets ignored: rollout latency can often be hidden with parallelism. If the execution substrate is reasonably fast, teams may choose the simpler system and add more CPU workers, because a few extra CPU-hours usually matter less than keeping the GPU training loop productive.
The problem appears when the execution layer is slow, variable, or operationally complex enough that parallelism stops being a clean escape hatch. Cold-start and scheduling overheads are already well-known systems problems in serverless computing; coding-agent RL brings a similar issue into the training loop. More workers can hide latency from the critical path, but they do not remove the underlying cost. They increase the amount of infrastructure held open, the scheduling burden, and the number of moving parts needed to keep fresh trajectories flowing back to the policy.
That is why we compare infrastructure archetypes rather than only sandbox vendors. Docker, EC2, Kubernetes, ECS/Fargate, and Daytona represent different paths teams might reasonably take when building a coding-agent rollout system. The goal is not to declare a universal winner. It is to make the execution layer measurable, because for coding-agent RL it is part of the training system.
Toward a Rollout-Native Training Stack
As RL post-training shifts from lightweight simulators to coding agents that operate inside real software environments, the environment is no longer a negligible part of the training loop.
GPU-hours remain important, but they do not fully describe the cost of producing useful gradients. Rollout throughput depends on how quickly environments can be scheduled, created, acted in, and reset.
The right solution depends on where a team starts. Teams with mature Kubernetes infrastructure may close much of the gap with scheduler tuning, warm pools, caching, and stronger isolation. Teams without that platform investment face a harder build-or-buy decision: build a pooled, low-latency execution layer themselves, or use a hosted sandbox layer like Daytona to avoid owning that infrastructure from day one. And for GPU-bound workloads, or agents with few external actions, this overhead may not matter yet.
No substrate wins universally. Coding-agent RL should measure the execution layer before optimizing around it.
RL Infra Bench Repo
Explore the open-source repo behind our RL infrastructure benchmark work and review the code, data, and artifacts supporting our essay claims.
References
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
SWE-Gym: An Open Environment for Training Software Engineering Agents
SWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training Song
Cold Start Latency in Serverless Computing: A Systematic Review, Taxonomy, and Future Directions

