This guide demonstrates how to use Daytona sandboxes to safely execute hundreds of code completions in parallel during reinforcement learning training.
We use TRL’s GRPOTrainer together with 500 Daytona sandboxes evaluating completions concurrently, in order to train the Qwen3-1.7B-Base model on some basic code-writing tasks.
1. Workflow Overview
This guide presents a simple, self-contained script that performs reinforcement learning training of Qwen3-1.7B-Base. In particular, we use reinforcement learning with verifiable rewards, with the reward being computed from the test pass rate of model-written functions.
The training loop consists of following steps:
- Generate: The model produces many code completions for each prompt (e.g., 250 completions per prompt per step)
- Evaluate: Each completion runs in its own Daytona sandbox against a test suite
- Reward: Completions that pass more tests get higher rewards; errors or banned patterns get negative rewards
- Update: GRPO reinforces completions that scored above their group average
The evaluation step happens in parallel across all 500 sandboxes. The sandboxes are spawned once at the start of the training and reused throughout it, and cleaned up after the training completes.
2. Setup
Clone the Repository
Clone the Daytona repository and navigate to the example directory:
git clone https://github.com/daytonaio/daytona.gitcd daytona/guides/python/reinforcement-learning/trlCreate Virtual Environment
python3 -m venv venvsource venv/bin/activate # On Windows: venv\Scripts\activateInstall Dependencies
pip install -e .This installs:
daytona- Daytona SDK for sandbox managementtrl[vllm]- TRL with vLLM integration for fast inferencedatasets- HuggingFace datasets librarypython-dotenv- Environment variable management
Configure Environment
Get your Daytona API key from the Daytona Dashboard and create a .env file:
DAYTONA_API_KEY=your_daytona_api_key3. Understanding the Code
Let’s walk through the key components of the training script.
Task Definitions
The script defines coding tasks as prompts with test cases. Note that the prompts are written in completion mode rather than QA mode because Qwen3-1.7B-Base is a base rather than an instruct model. Each task specifies what the model should generate and how to verify correctness:
SORTING_PROMPT = """# I've been fiddling with different ways to sort numbers in Python.# At first I just used sorted() and list.sort(), but then I decided to try# my hand at writing some original sorting functions. And I succeeded!# I don't call sorted(), list.sort(), heapq, or use any imports here - just plain# Python and an original algorithm.def sort_numbers(xs: list[int]) -> list[int]: \"\"\"Sort a list of integers in ascending order.
Args: xs: A list of integers to be sorted.
Returns: A new list containing the same integers, sorted from smallest to largest. \"\"\""""
TASKS = { "sorting": { "prompt": SORTING_PROMPT, "func_name": "sort_numbers", "banned_patterns": ["sorted(", ".sort(", "heapq", "import ", "__import__"], "tests": [ "[]", "[1, 3, 2]", "[random.randint(-1000, 1000) for _ in range(200)]", "[random.randint(-100, 100) for _ in range(1000)]", "list(range(0, 100)) + list(range(200, 100, -1)) + list(range(200, 300))", ], "reference": "sorted", }, # Additional tasks can be added here...}Each task includes:
- prompt: The code context the model continues from
- func_name: The function name being implemented
- banned_patterns: Patterns that disqualify a completion (e.g., using built-in
sorted()) - tests: Test inputs to verify correctness
- reference: The reference implementation to compare against
How Prompts Become Completions
When the model receives the sorting prompt, it continues the text as if completing a Python file. A typical model output might look like:
if len(xs) <= 1: return xs pivot = xs[len(xs) // 2] left = [x for x in xs if x < pivot] middle = [x for x in xs if x == pivot] right = [x for x in xs if x > pivot] return sort_numbers(left) + middle + sort_numbers(right)
# Example usage:print(sort_numbers([3, 1, 4, 1, 5, 9, 2, 6]))Notice the model generates the indented function body, but may also add extra content after (comments, example usage, etc.). The sanitize_completion function extracts only the indented lines that form the function body:
def sanitize_completion(text: str) -> str: # Take lines until the first unindented line lines = text.splitlines() kept: List[str] = [] for line in lines: if line and (not line.startswith(" ")): break kept.append(line) return "\n".join(kept).rstrip()After sanitization, the example above becomes just the function body:
if len(xs) <= 1: return xs pivot = xs[len(xs) // 2] left = [x for x in xs if x < pivot] middle = [x for x in xs if x == pivot] right = [x for x in xs if x > pivot] return sort_numbers(left) + middle + sort_numbers(right)Sandbox Pool Management
We create the sandbox pool upfront and reuse sandboxes throughout training:
EFFECTIVE_BATCH_SIZE = 500# We evaluate each completion concurrently, in its own sandbox,# so we spawn EFFECTIVE_BATCH_SIZE number of sandboxes.
async def _create_sandbox_pool_async( daytona: AsyncDaytona, n: int = 10) -> List[AsyncSandbox]: print(f"Creating {n} sandboxes...") tasks = [daytona.create() for _ in range(n)] sandboxes = await asyncio.gather(*tasks) print(f"Successfully created all {len(sandboxes)} sandboxes") return list(sandboxes)
async def _cleanup_sandbox_pool_async(sandbox_pool: List[AsyncSandbox]) -> None: if not sandbox_pool: return print("Cleaning up sandboxes...") tasks = [sandbox.delete() for sandbox in sandbox_pool] results = await asyncio.gather(*tasks, return_exceptions=True) for r in results: if isinstance(r, Exception): print(f" Sandbox delete error: {type(r).__name__}: {r}") print("All sandboxes cleaned up")The pool size (500) is chosen to match the total batch size (per_device_train_batch_size * gradient_accumulation_steps), ensuring every completion in a batch can be evaluated in parallel.
Code Evaluation
The main evaluation function ties everything together - it sanitizes the completion, checks for banned patterns, builds the test harness, executes it in a sandbox, and parses the results:
async def evaluate_single_completion_async( sandbox: AsyncSandbox, raw_completion: str, prompt: str,) -> EvalResult: task = PROMPT_TO_TASK[prompt] num_task_tests = len(task["tests"]) body = sanitize_completion(raw_completion)
if not body.strip(): return _fail_result(num_task_tests) if has_banned_pattern(body, task): return _fail_result(num_task_tests)
code = build_test_harness(task, body)
try: response = await sandbox.code_interpreter.run_code( code, timeout=MAX_TIMEOUT_SECONDS ) except DaytonaTimeoutError: print( f"Completion timed out after {MAX_TIMEOUT_SECONDS}s " f"in sandbox {getattr(sandbox, 'id', '?')}" ) return _fail_result(num_task_tests) except Exception as e: print( f"Error evaluating completion in sandbox {getattr(sandbox, 'id', '?')}: " f"{type(e).__name__}: {e}", ) return _fail_result(num_task_tests)
if response.error is not None: return _fail_result(num_task_tests) raw_output = response.stdout.strip() if not raw_output: return _fail_result(num_task_tests) last_line = raw_output.splitlines()[-1] try: results = json.loads(last_line) except Exception: return _fail_result(num_task_tests) correct = results.get("results", [])
return { "no_error": True, "num_passed": sum(bool(x) for x in correct), "num_tests": len(correct), }The Test Harness
The build_test_harness function combines the original prompt, the model’s completion, and a test runner into Python code that ultimately executes on the sandbox:
def build_test_harness(task: Dict[str, Any], function_body: str) -> str: prompt = task["prompt"] func_name = task["func_name"] reference_function = task["reference"] tests = task["tests"]
tests_tuple = ",\n ".join(tests)
return f"""{prompt}{function_body}
import jsonimport randomrandom.seed(0)
def _kadane(xs): max_sum = current = xs[0] for x in xs[1:]: current = max(x, current + x) max_sum = max(max_sum, current) return max_sum
def _run_tests(): tests = ( {tests_tuple} ) results = [] for xs in tests: try: out = {func_name}(xs.copy()) expected = {reference_function}(xs.copy()) results.append(out == expected) except Exception: results.append(False) print(json.dumps({{"results": results}}))
if __name__ == "__main__": _run_tests()"""For the sorting task with a quicksort completion, the assembled code looks like:
# I've been fiddling with different ways to sort numbers in Python...def sort_numbers(xs: list[int]) -> list[int]: """Sort a list of integers in ascending order...""" if len(xs) <= 1: return xs pivot = xs[len(xs) // 2] left = [x for x in xs if x < pivot] middle = [x for x in xs if x == pivot] right = [x for x in xs if x > pivot] return sort_numbers(left) + middle + sort_numbers(right)
import jsonimport randomrandom.seed(0)
def _run_tests(): tests = ( [], [1, 3, 2], [random.randint(-1000, 1000) for _ in range(200)], # ... more tests ) results = [] for xs in tests: try: out = sort_numbers(xs.copy()) expected = sorted(xs.copy()) results.append(out == expected) except Exception: results.append(False) print(json.dumps({"results": results}))
if __name__ == "__main__": _run_tests()When executed in the sandbox, this prints JSON to stdout:
{"results": [true, true, true, false, true]}The evaluation function parses this JSON to count how many tests passed.
Banned Pattern Detection
Before running code in the sandbox, we check for banned patterns. This prevents the model from “cheating” by using built-in functions:
def has_banned_pattern(text: str, task: Dict[str, Any]) -> bool: banned = task.get("banned_patterns", []) if not banned: return False lowered = text.lower() return any(p.lower() in lowered for p in banned)For the sorting task, banned patterns include sorted(, .sort(, heapq, and import. If the model generates return sorted(xs), it gets a reward of -1.0 instead of being executed - we want the model to learn to write actual sorting algorithms, not to call built-in functions.
Parallel Batch Evaluation
The batch evaluator distributes completions across the sandbox pool:
async def _evaluate_batch_async( sandbox_pool: List[AsyncSandbox], completions: List[str], prompts: List[str]) -> List[EvalResult]: print( f"Evaluating {len(completions)} completions in parallel across " f"{len(sandbox_pool)} sandboxes..." )
async def run_one( i: int, sandbox: AsyncSandbox, completion: str, prompt: str ) -> EvalResult: task = PROMPT_TO_TASK[prompt] num_task_tests = len(task["tests"]) try: stats = await evaluate_single_completion_async(sandbox, completion, prompt) print(f" Completion {i + 1}/{len(completions)} done") return stats except Exception as e: print( f" Completion {i + 1}/{len(completions)} failed: " f"{type(e).__name__}: {e}" ) return _fail_result(num_task_tests)
tasks = [ run_one(i, sandbox_pool[i % len(sandbox_pool)], completion, prompt) for i, (completion, prompt) in enumerate(zip(completions, prompts)) ]
stats_list = await asyncio.gather(*tasks) print(f" Done: {len(completions)}/{len(completions)} completions evaluated")
return stats_listEach completion is assigned to a sandbox using round-robin distribution (i % len(sandbox_pool)), ensuring even load distribution.
Reward Function
The reward function receives the results from the sandboxes and computes the corresponding scalar reward.
def reward_func(prompts, completions, **kwargs): stats_list = run_async( _evaluate_batch_async(sandbox_pool, completions, prompts) ) rewards = [] for s in stats_list: if not s["no_error"]: rewards.append(-1.0) elif s["num_tests"] == 0: rewards.append(0.0) else: rewards.append(s["num_passed"] / s["num_tests"]) return rewardsThe reward scheme:
- -1.0: Error, timeout, or banned pattern detected
- 0.0: No tests were present (shouldn’t happen with valid tasks)
- 0.0 to 1.0: Fraction of tests passed
Bridging Sync and Async
TRL’s GRPOTrainer expects a synchronous reward function, but the Daytona SDK uses async/await for parallel sandbox operations. We bridge these two worlds with a helper:
def main(): # Create a dedicated event loop for async operations loop = asyncio.new_event_loop() asyncio.set_event_loop(loop)
def run_async(coro: Awaitable[Any]) -> Any: """Run async code from sync context.""" return loop.run_until_complete(coro)
# ... training code ...
def reward_func(prompts, completions, **kwargs): # This sync function is called by TRL # We use run_async to call our async evaluation stats_list = run_async( _evaluate_batch_async(sandbox_pool, completions, prompts) ) # ... compute rewards ... return rewardsThis pattern lets us keep the async parallelism benefits of the Daytona SDK while working within TRL’s synchronous training loop. The run_async helper blocks until all 500 parallel sandbox evaluations complete, then returns the results.
Training Configuration
The GRPO trainer is configured with these parameters:
training_args = GRPOConfig( output_dir="training_results", per_device_train_batch_size=20, # batch size chosen so the training runs comfortably on a single 80GB GPU, # if running this on a GPU with less memory, reduce the batch size accordingly gradient_accumulation_steps=25, num_generations=EFFECTIVE_BATCH_SIZE // len(TASKS), max_prompt_length=256, max_completion_length=512, learning_rate=8e-6, num_train_epochs=1, logging_steps=1, report_to="none", max_steps=8, bf16=True, use_vllm=True, vllm_mode="colocate", vllm_gpu_memory_utilization=0.15, gradient_checkpointing=True, loss_type="dapo", beta=0.01,)Key settings explained:
Batch size and sandbox pool alignment:
per_device_train_batch_size (20) × gradient_accumulation_steps (25) = 500This equals EFFECTIVE_BATCH_SIZE. Each training step generates exactly 500 completions, and we have exactly 500 sandboxes - so every completion evaluates in parallel with no waiting. If we had fewer sandboxes, some completions would queue up. If we had more, sandboxes would sit idle.
vLLM colocate mode:
use_vllm=True,vllm_mode="colocate",vllm_gpu_memory_utilization=0.15,This runs vLLM for fast inference on the same GPU as training. We use 15% of the GPU’s memory for model generation, and the rest for training (optimizer states).
Generation settings:
num_generations=EFFECTIVE_BATCH_SIZE // len(TASKS): Generate 250 completions per prompt (500 / 2 tasks). With 2 prompts (sorting and max_subarray), that’s 500 total per stepmax_completion_length=512: Limit completion length to prevent runaway generation
4. Running the Training
Start training with:
python train.pyYou’ll see output like:
Creating 500 sandboxes...Successfully created all 500 sandboxesEvaluating 500 completions in parallel across 500 sandboxes... Completion 1/500 done Completion 2/500 done ... Done: 500/500 completions evaluatedAfter training completes, metrics are saved to training_results/metrics.jsonl and the model is saved as training_results/checkpoint-8.
5. Example Evaluation Walkthrough
Let’s trace through what happens when evaluating a single completion:
Step 1: Model generates a completion
The model receives the sorting prompt and generates:
if len(xs) <= 1: return xs pivot = xs[0] less = [x for x in xs[1:] if x <= pivot] greater = [x for x in xs[1:] if x > pivot] return sort_numbers(less) + [pivot] + sort_numbers(greater)
# Testprint(sort_numbers([3, 1, 2]))Step 2: Sanitization extracts the function body
sanitize_completion keeps only the indented lines:
if len(xs) <= 1: return xs pivot = xs[0] less = [x for x in xs[1:] if x <= pivot] greater = [x for x in xs[1:] if x > pivot] return sort_numbers(less) + [pivot] + sort_numbers(greater)Step 3: Check for banned patterns
has_banned_pattern scans for sorted(, .sort(, heapq, import. None found, so we proceed.
Step 4: Build the test harness
build_test_harness assembles the full script: prompt + completion + test runner. This becomes ~50 lines of executable Python.
Step 5: Execute in sandbox
response = await sandbox.code_interpreter.run_code(code, timeout=1)The sandbox runs the code and returns within the 1-second timeout.
Step 6: Parse results
The test runner printed:
{"results": [true, true, true, true, true]}We parse this from response.stdout:
results = json.loads(response.stdout.strip().splitlines()[-1])# {"results": [true, true, true, true, true]}Step 7: Compute reward
All 5 tests passed:
reward = 5 / 5 # = 1.0This completion gets a perfect reward of 1.0, reinforcing the model to generate similar quicksort implementations.
6. Training Results
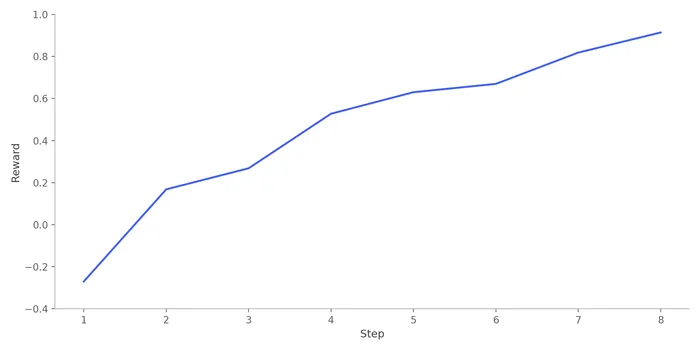
The plot below shows average rewards over training steps. At the start, the model is very rarely writing functions that meet the task specifications, and it is often writing code that either errors out or times out. Given our large effective batch size of 500, the model achieves near-perfect performance after only 8 steps.
7. Adding Custom Tasks
To add a new coding task, extend the TASKS dictionary:
TASKS = { "your_task": { "prompt": "Your prompt here...", "func_name": "function_name", "banned_patterns": ["patterns", "to", "ban"], "tests": [ "test_input_1", "test_input_2", ], "reference": "reference_function", },}The reference function should be defined in the test harness that build_test_harness generates.
8. Configuration Options
| Parameter | Default | Description |
|---|---|---|
EFFECTIVE_BATCH_SIZE | 500 | Effective batch size, also equal to the number of parallel sandboxes |
MAX_TIMEOUT_SECONDS | 1 | Timeout per code execution |
MODEL_NAME | Qwen/Qwen3-1.7B-Base | Base model to train |
Key advantages of this approach:
- Massive parallelism: 500 sandboxes evaluate completions simultaneously
- Safe execution: Generated code runs in isolated environments, protecting your system
- Fast feedback: vLLM + parallel evaluation minimizes training iteration time
- Extensible: Add new coding tasks by defining prompts and test cases